Stephen King
REST API
Development
API Design

Typescript
Typed superset of Javascript

Postgres
Relational Database and management system

Prisma
Open source Node and TS ORM

Javascript
For interaction design testing
The Goal
With 65 novels/novellas, over 200 short stories, and countless memorable characters I wanted a way to access this information programatically. Moreover, many of his works are loosely connected in a 'King Universe', with different characters and locations popping up accross multiple fictions. As a fan, those relationships have always facinated me and as developer they seemed to fit perfectly in a strucutred database.
The Data Challenge
What, Where, How
Lets start with the easiest question - How am I going to get this data? Scraping, both with Python's
BeautifulSoup and Javascript's Cheerio.
What type of data should I
include? obviously I needed basic bibliophic info about the works
like publish date, publisher, page count etc.. But I also wanted
character data - specifically books they were in. On top of that I
needed a common data point shared between entities the so that I
could make those relationships programmically.
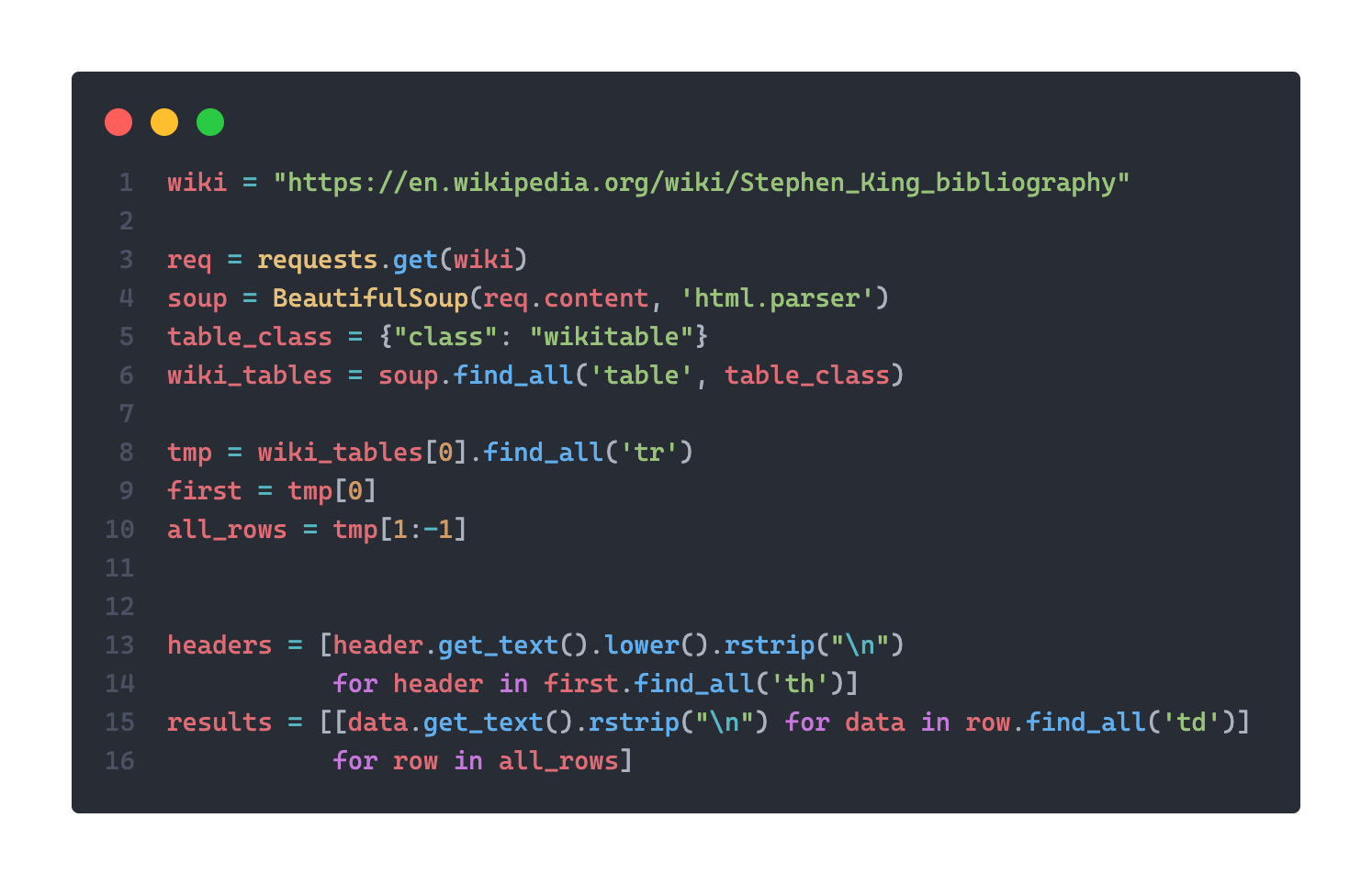
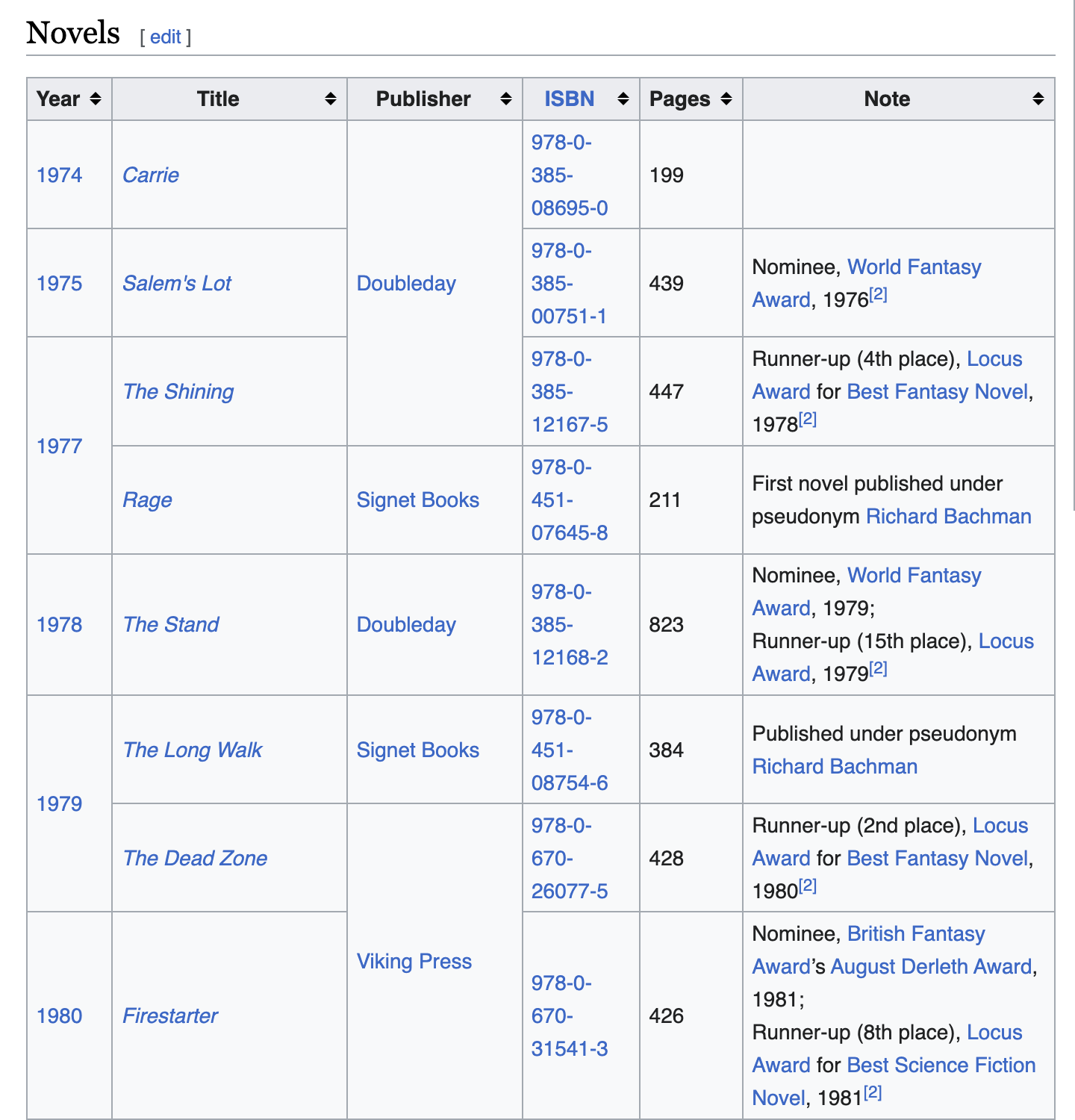
Where am I going to source my data? I initially turned to Wikipedia, which provides a comprehensive list of Stephen King's entire body of work, including bibliographic data in a scraper-friendly format. However, I encountered challenges when attempting to extract character information due to inconsistent formatting across individual Wikipedia pages for King's works. Fortunately, I found an alternative source in the form of dedicated fan wikis related to Stephen King's work. Specifically, I leveraged the information available on the Fandom website, which offered a wealth of character data relevant to my project. This alternative source allowed me to successfully scrape and integrate character information into the API.